XIOS3 demonstrator
Overview
NEMO version 5.0 includes a new configuration: cfgs/X3_ORCA2_ICE_PISCES which is a
variation on the ORCA2_ICE_PISCES reference configuration designed to illustrate the
XML changes required to utilise the new XIOS3 functionalities. This is in advance of any
detailed documentation on XIOS3 and is based mainly on material presented by the XIOS
developers at a coupling workshop in 2023. The slides from that presentation can be found
here .
The X3_ORCA2_ICE_PISCES demonstrator is based on the SETTE tests for ORCA2_ICE_PISCES.
Traditionally, this is run with 32 Ocean cores and 4 XIOS servers producing one-file
output. This XIOS3 example has also been run with 32 ocean cores but has used 12 XIOS3
servers to produce one-file output via various pools and services. Whilst, in this case,
not much has been gained, the ability to control exactly how the xios resources are
deployed and employed should make for robust solutions in more demanding cases. This has
already been successfully tested in an eORCA025 configuration where 1019 ocean cores have
reliably produced one-file output via 52 xios servers. This latter example is illustrated
on a XIOS ticket at:
XIOS forge ticket 190 .
For now, this simpler example will be used to explain the options and highlight the XML
changes required to make it happen. First, here is a schematic of the example:
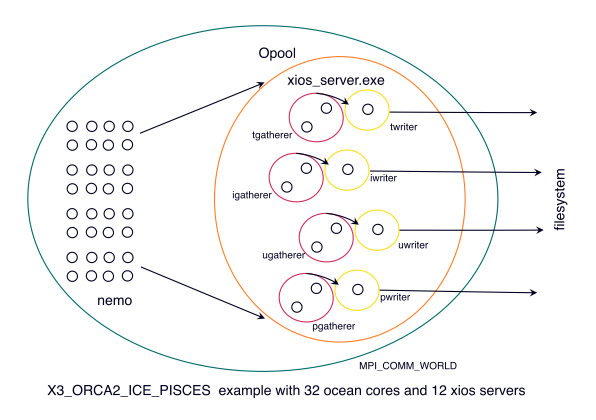
The idea is that, instead of all fields going to all xios servers, subsets of xios servers are assigned to gather different groups of fields. These “gatherer” services then send the collated fields to dedicated “writer” services. In this example, separate gatherer services, with 2-cores each, are used for: T- and W-grid variables; ice fields; U- and V-grid variables and passive tracer fields. These services are named: tgatherer, igatherer, ugatherer and pgatherer. Larger configurations may elect to have separate services for different output frequencies too to spread the memory footprint. Each of these gatherer services has an associated writer service: twriter; iwriter; uwriter and pwriter. Each writer service has only one server process assigned to it, thus guaranteeing one-file output. With larger configurations, more writing processes may be required per writing service but it is expected that numbers can be kept low enough for the “one_file” activation of netcdf4 output to be suitably robust and efficient.
Changes to iodef.xml
All of this is set up via xml tags in the iodef.xml file, namely:
<?xml version="1.0"?>
<simulation>
<!-- ============================================================================================ -->
<!-- XIOS3 context -->
<!-- ============================================================================================ -->
<context id="xios" >
<variable_definition>
<variable_group id="buffer">
<variable id="min_buffer_size" type="int">400000</variable>
<variable id="optimal_buffer_size" type="string">performance</variable>
</variable_group>
<variable_group id="parameters" >
<variable id="using_server" type="bool">true</variable>
<variable id="info_level" type="int">0</variable>
<variable id="print_file" type="bool">false</variable>
<variable id="using_server2" type="bool">false</variable>
<variable id="transport_protocol" type="string" >p2p</variable>
<variable id="using_oasis" type="bool">false</variable>
</variable_group>
</variable_definition>
<pool_definition>
<pool name="Opool" nprocs="12">
<service name="tgatherer" nprocs="2" type="gatherer"/>
<service name="igatherer" nprocs="2" type="gatherer"/>
<service name="ugatherer" nprocs="2" type="gatherer"/>
<service name="pgatherer" nprocs="2" type="gatherer"/>
<service name="twriter" nprocs="1" type="writer"/>
<service name="uwriter" nprocs="1" type="writer"/>
<service name="iwriter" nprocs="1" type="writer"/>
<service name="pwriter" nprocs="1" type="writer"/>
</pool>
</pool_definition>
</context>
<!-- ============================================================================================ -->
<!-- NEMO CONTEXT add and suppress the components you need -->
<!-- ============================================================================================ -->
<context id="nemo" default_pool_writer="Opool" default_pool_gatherer="Opool" src="./context_nemo.xml"/> <!-- NEMO -->
</simulation>
Much of this will be familiar and carries over from XIOS2. The new pool_definition tag
and the syntax of its contents is also straight-forward. There are a couple of subtleties
to point out:
<variable id="transport_protocol" type="string" >p2p</variable>
This is a new transport_protocol using point to point communication and has proven to be the most reliable in these tests.
<context id="nemo" default_pool_writer="Opool" default_pool_gatherer="Opool" src="./context_nemo.xml"/>
New attributes added to the context tag which declare the default pool from which named gatherers and writers will be selected.
Changes to file_defs
Next, to make use of these services they have to be assigned at the file level. For example,
here are the changes in the file_def_nemo-ice.xml:
--- ../../ORCA2_ICE_PISCES/EXPREF/file_def_nemo-ice.xml 2023-09-15 16:57:00.039299000 +0100
+++ file_def_nemo-ice.xml 2023-09-21 13:10:36.750776000 +0100
@@ -9,10 +9,10 @@
============================================================================================================
-->
- <file_definition type="one_file" name="@expname@_@freq@_@startdate@_@enddate@" sync_freq="1mo" min_digits="4">
+ <file_definition type="one_file" compression_level="1" name="@expname@_@freq@_@startdate@_@enddate@" sync_freq="1mo" min_digits="4">
<file_group id="5d" output_freq="5d" output_level="10" enabled=".TRUE."> <!-- 5d files -->
- <file id="file21" name_suffix="_icemod" description="ice variables" enabled=".true." >
+ <file id="file21" name_suffix="_icemod" mode="write" gatherer="igatherer" writer="iwriter" using_server2="true" description="ice variables" enabled=".true." >
<!-- ice mask -->
<field field_ref="icemask" name="simsk" />
@@ -89,7 +89,7 @@
</file>
- <file id="file22" name_suffix="_SBC_scalar" description="scalar variables" enabled=".true." >
+ <file id="file22" compression_level="0" name_suffix="_SBC_scalar" mode="write" gatherer="igatherer" writer="iwriter" using_server2="true" description="scalar variables" enabled=".true." >
<!-- global contents -->
<field field_ref="ibgvol_tot" name="ibgvol_tot" />
<field field_ref="sbgvol_tot" name="sbgvol_tot" />
@@ -123,7 +123,7 @@
<file_group id="4h" output_freq="4h" output_level="10" enabled=".TRUE."/> <!-- 4h files -->
<file_group id="6h" output_freq="6h" output_level="10" enabled=".TRUE."/> <!-- 6h files -->
- <file_group id="1m" output_freq="1mo" output_level="10" enabled=".TRUE."> <!-- real monthly files -->
+ <file_group id="1m" compression_level="0" output_freq="1mo" output_level="10" enabled=".TRUE."> <!-- real monthly files -->
<!-- To compute transport through straits : need to read ice mask at ice iteration at freq_offset = 1mo - nn_fsbc
<file id="file23" name_suffix="_strait_ice" description="transport variables through straits" >
with corresponding changes in the other file_def files. Note that compression_level
attributes have also been added here, more about that to follow.
Other XML changes
A couple of other XML tags are transitioning to new names. To avoid generating warnings concerning the use of the old names it is recommended to make the following changes before testing this new capability:
zoom_axis ---> extract_axis in axis_def_nemo.xml
and the change of all:
zoom_domain ---> extract_domain in domain_def_nemo.xml
There are additional changes in the field_def*.xml files and the
domain_def_nemo.xml and axis_def_nemo.xml files which are to do with the next
stage of exercising control over dataset chunking and compression.
Chunking and compression
One goal of making one file output from XIOS more reliable is to eliminate the need for any further post-processing of the output. With this in mind, it may be necessary to exercise control over the chunk sizes used for the output files since the optimum choice will depend on future access requirements.
XIOS3 has a selection of XML attributes that control the chunk sizes but achieving particular target chunk dimensions isn’t straight-forward. These attributes are a range of domain, axis and field settings listed here:
attribute name
attribute type
default setting
chunking_weight_i
domain
1.0
chunking_weight_j
domain
1.0
chunking_weight
axis
1.0
chunking_blocksize_target
field
20.0 (MB)
prec
field
4 or 8
compression_level
file
0
The last does not actually affect the chunk size but is included as a reminder that one major reason to activate chunking is to allow efficient dataset compression (which is off by default).
Ticket #191 on the XIOS
forge contains an explanation of the algorithm that is used. Based on this, a chunk size
calculator has been added in tools/MISCELLANEOUS/calc_xios_chunks.py:
python3 calc_xios_chunks.py --help
usage: calc_xios_chunks.py [-h] [-i ISIZE] [-j JSIZE] [-k KSIZE] [-t TARGET]
[-p PREC] [-wi WI] [-wj WJ] [-wk WK]
Calculate netCDF4 chunks sizes that XIOS will use based on domain size
and chunk_weight and chunk_blocksize_targets set as XML attributes, e.g.:
python3 ./calc_xios_chunks.py -i isize -j jsize -k ksize
-t target -p fp_precision
-wi wgt_i -wj wgt_j -wk wgt_k
All arguments are optional with default settings equivalent to
XIOS defaults with a eORCA025-size domain
optional arguments:
-h, --help show this help message and exit
-i ISIZE First dimension size of the domain (usually longitudinal) [1440]
-j JSIZE Second dimension size of the domain (usually latitudinal) [1206]
-k KSIZE Third dimension size of the domain (usually depth) [75]
-t TARGET Target chunk blocksize in MB [20.0]
-p PREC Floating-point byte-size of op variables, (usually 4 or 8) [4]
-wi WI Weight applied to the first dimension [1.0]
-wj WJ Weight applied to the second dimension [1.0]
-wk WK Weight applied to the third dimension [1.0]
So for ORCA2 with default settings we have:
python3 calc_xios_chunks.py -i 180 -j 148 -k 31
-----------------------------------------------------
XYZ domain size : 180 x 148 x 31
Target chunksize : 20 MB, FP precision: 4
i- j- and k- weights: 1.0 1.0 1.0
4D TZYX chunk sizes : 1 31 148 180
3D TYX chunk sizes : 1 148 180
-----------------------------------------------------
Thus, without any intervention, the default behaviour for ORCA2 is to have the entire model volume as a single chunk. With compression, this can be wasteful since any future access, even for a single datum, has to retrieve and uncompress the entire chunk.
Adjusting the various weights and block size target will change this, for example:
python3 calc_xios_chunks.py -i 180 -j 148 -k 31 -wk 12. -t 3
-----------------------------------------------------
XYZ domain size : 180 x 148 x 31
Target chunksize : 3 MB, FP precision: 4
i- j- and k- weights: 1.0 1.0 12.0
4D TZYX chunk sizes : 1 6 148 180
3D TYX chunk sizes : 1 148 180
-----------------------------------------------------
which is the choice provided with the demonstrator. These settings can be seen in situ by examining the XML files provided with the demonstrator. I.e.:
grep -e chunking_ -e compression *.xml
axis_def_nemo.xml: <axis id="deptht" long_name="Vertical T levels" unit="m" positive="down" chunking_weight="12.0" />
axis_def_nemo.xml: <axis id="deptht300" axis_ref="deptht" chunking_weight="12.0" >
axis_def_nemo.xml: <axis id="depthu" long_name="Vertical U levels" unit="m" positive="down" chunking_weight="12.0" />
axis_def_nemo.xml: <axis id="depthv" long_name="Vertical V levels" unit="m" positive="down" chunking_weight="12.0" />
axis_def_nemo.xml: <axis id="depthw" long_name="Vertical W levels" unit="m" positive="down" chunking_weight="12.0" />
axis_def_nemo.xml: <axis id="depthf" long_name="Vertical F levels" unit="m" positive="down" chunking_weight="12.0" />
axis_def_nemo.xml: <axis id="nlayice" long_name="Ice layer" unit="1" chunking_weight="1.0" />
domain_def_nemo.xml: <domain id="grid_T" long_name="grid T" chunking_weight_i="1.0" chunking_weight_j="1.0" />
domain_def_nemo.xml: <domain id="grid_T_inner" long_name="grid T inner" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_U" long_name="grid U" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_U_inner" long_name="grid U inner" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_V" long_name="grid V" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_V_inner" long_name="grid V inner" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_W" long_name="grid W" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_W_inner" long_name="grid W inner" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_F" long_name="grid F" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
domain_def_nemo.xml: <domain id="grid_F_inner" long_name="grid F inner" chunking_weight_i="1.0" chunking_weight_j="1.0"/>
field_def_nemo-ice.xml: <field_group id="SBC" chunking_blocksize_target="3.0" > <!-- time step automatically defined based on nn_fsbc -->
field_def_nemo-oce.xml: <field_group id="all_ocean" chunking_blocksize_target="3.0">
field_def_nemo-pisces.xml: <field_group id="all_pisces" chunking_blocksize_target="3.0">
file_def_nemo-ice.xml: <file_definition type="one_file" compression_level="1" name="@expname@_@freq@_@startdate@_@enddate@" sync_freq="1mo" min_digits="4">
file_def_nemo-ice.xml: <file id="file22" compression_level="0" name_suffix="_SBC_scalar" mode="write" gatherer="igatherer" writer="iwriter" using_server2="true" description="scalar variables" enabled=".true." >
file_def_nemo-ice.xml: <file_group id="1m" compression_level="0" output_freq="1mo" output_level="10" enabled=".TRUE."> <!-- real monthly files -->
file_def_nemo-oce.xml: <file_definition type="one_file" compression_level="1" name="@expname@_@freq@_@startdate@_@enddate@" sync_freq="1mo" min_digits="4">
file_def_nemo-oce.xml: <file id="file15" compression_level="0" name_suffix="_scalar" mode="write" gatherer="tgatherer" writer="twriter" using_server2="true" description="scalar variables" >
file_def_nemo-pisces.xml: <file_definition type="one_file" compression_level="1" name="@expname@_@freq@_@startdate@_@enddate@" sync_freq="1mo" min_digits="4">
file_def_nemo-pisces.xml: <file id="file31" compression_level="0" name_suffix="_bioscalar" mode="write" gatherer="pgatherer" writer="pwriter" using_server2="true" description="pisces sms variables" >
With this small model it is difficult to force division of the primary axes but it can be done. Perhaps this is a reasonable choice if future access is likely to favour either Northern or Southern hemispheres:
python3 calc_xios_chunks.py -i 180 -j 148 -k 31 -wj 2 -wk 12. -t 1
-----------------------------------------------------
XYZ domain size : 180 x 148 x 31
Target chunksize : 1 MB, FP precision: 4
i- j- and k- weights: 1.0 2.0 12.0
4D TZYX chunk sizes : 1 8 74 180
3D TYX chunk sizes : 1 148 180
-----------------------------------------------------
Summary of changes
The contents of cfgs/X3_ORCA2_ICE_PISCES/EXPREF parallel those of the parent
ORCA2_ICE_PISCES with local copies of any changed files. This includes some files that
were originally symbolic links to files in the SHARED directory. Files which are
symbolic links to files in the SHARED directory have @ appended to their name in the
following table:
ORCA2_ICE_PISCES/EXPREF
sum
X3_ORCA2_ICE_PISCES/EXPREF
sum
changed?
axis_def_nemo.xml@
53815
3
axis_def_nemo.xml
53184
3
yes
context_nemo.xml
08199
2
context_nemo.xml
08199
2
no
domain_def_nemo.xml@
17199
13
domain_def_nemo.xml
46480
14
yes
field_def_nemo-ice.xml@
32328
64
field_def_nemo-ice.xml
31824
64
yes
field_def_nemo-oce.xml@
13274
140
field_def_nemo-oce.xml
10094
140
yes
field_def_nemo-pisces.xml@
18919
33
field_def_nemo-pisces.xml
62713
33
yes
file_def_nemo-ice.xml
25184
9
file_def_nemo-ice.xml
28646
9
yes
file_def_nemo-oce.xml
31630
11
file_def_nemo-oce.xml
45129
11
yes
file_def_nemo-pisces.xml
53625
9
file_def_nemo-pisces.xml
16003
10
yes
grid_def_nemo.xml@
54429
11
grid_def_nemo.xml@
54429
11
no
iodef.xml
25161
2
iodef.xml
32297
3
yes
namelist_cfg
06454
36
namelist_cfg
06454
36
no
namelist_ice_cfg
00419
5
namelist_ice_cfg
00419
5
no
namelist_ice_ref@
49215
26
namelist_ice_ref@
49215
26
no
namelist_pisces_cfg
44377
6
namelist_pisces_cfg
44377
6
no
namelist_pisces_ref@
15677
30
namelist_pisces_ref@
15677
30
no
namelist_ref@
14435
124
namelist_ref@
14435
124
no
namelist_top_cfg
40559
12
namelist_top_cfg
40559
12
no
namelist_top_ref@
20216
13
namelist_top_ref@
20216
13
no